სიახლეებზე დაბრუნება

22 Feb, 2026
Georgian KenLM Language Model (3-gram)
KenLM 3-gram language model trained on Georgian (ქართული) text data
🦉 Georgian KenLM Language Model (3-gram)
KenLM 3-gram language model trained on Georgian (ქართული) text data, intended for ASR decoding and general language modeling.
- Language
ka(Georgian)- Model Type
- KenLM n-gram
- n-gram size
3-gram- Format
.arpa- Tooling
- KenLM
View on Hugging Face
Opens in a new tab
📂 Files
ge_model9.arpa— ARPA plaintext format
📚 Training Data
Trained on a curated collection of Georgian text from multiple domains:
- News articles
- Subtitles
- Books and web content
Data was cleaned, whitespace-tokenized, and normalized to standard Georgian orthography.
💬 Intended Use
Ideal for:
- Beam search decoding in ASR systems (e.g., Whisper, DeepSpeech, Vosk)
- Scoring and reranking ASR hypotheses
- Basic text modeling or Georgian spelling correction
Quick integration note
If you’re using a CTC decoder (e.g., pyctcdecode), you typically pair this .arpa
with a tokenizer/lexicon and plug it into beam search scoring.
22 Feb, 2026, 15:29
ყველა სიახლე
| სხვა სიახლეები
AI ქართულ სამართალში: როგორ ვასწავლეთ საგადასახადო კოდექსი ხელოვნურ ინტელექტს
1 week ago
B2B: Real-time Georgian speech transcription right on your desktop
1 month ago
ASR.GE - ხელოვნური ინტელექტი თქვენს სამედიცინო დაწესებულებაში
1 month ago

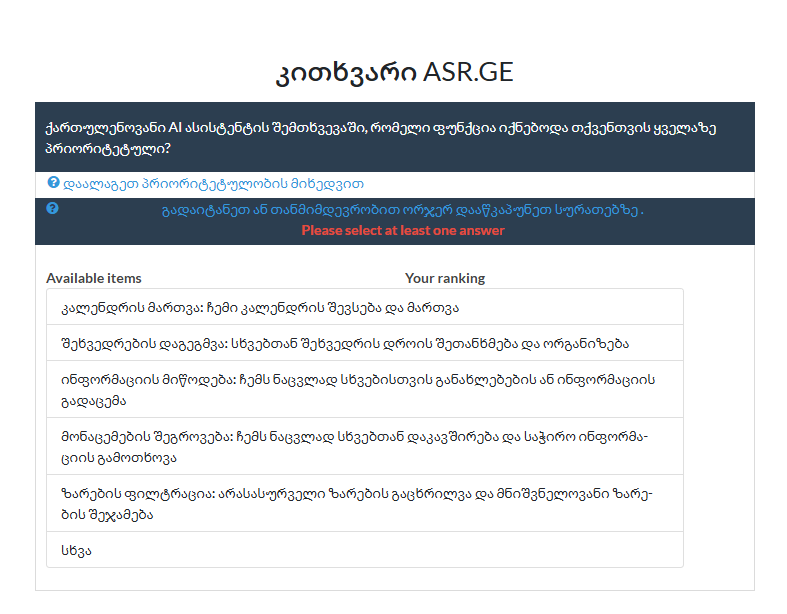
ქართული AI-ს მომავალი უფრო მეტია, ვიდრე უბრალოდ ჩატი. 🚀 - Survey | კვლევა
2 months ago